
2026年4月AI大模型排名:谷歌登顶,国产模型全面崛起
如果你最近还在用半年前选定的AI模型做业务,可能要重新看一看了。
Artificial Analysis 每72小时更新一次的 LLM 排行榜,目前已收录 317 个模型。这张榜单不是看论文发表数量,也不靠厂商自报,而是从实际 API 调用中采集智能指数、响应速度、成本和延迟这几个维度的实测数据。换句话说,它大致反映了”花钱买到的模型到底怎么样”。
智能指数前五,格局已经变了
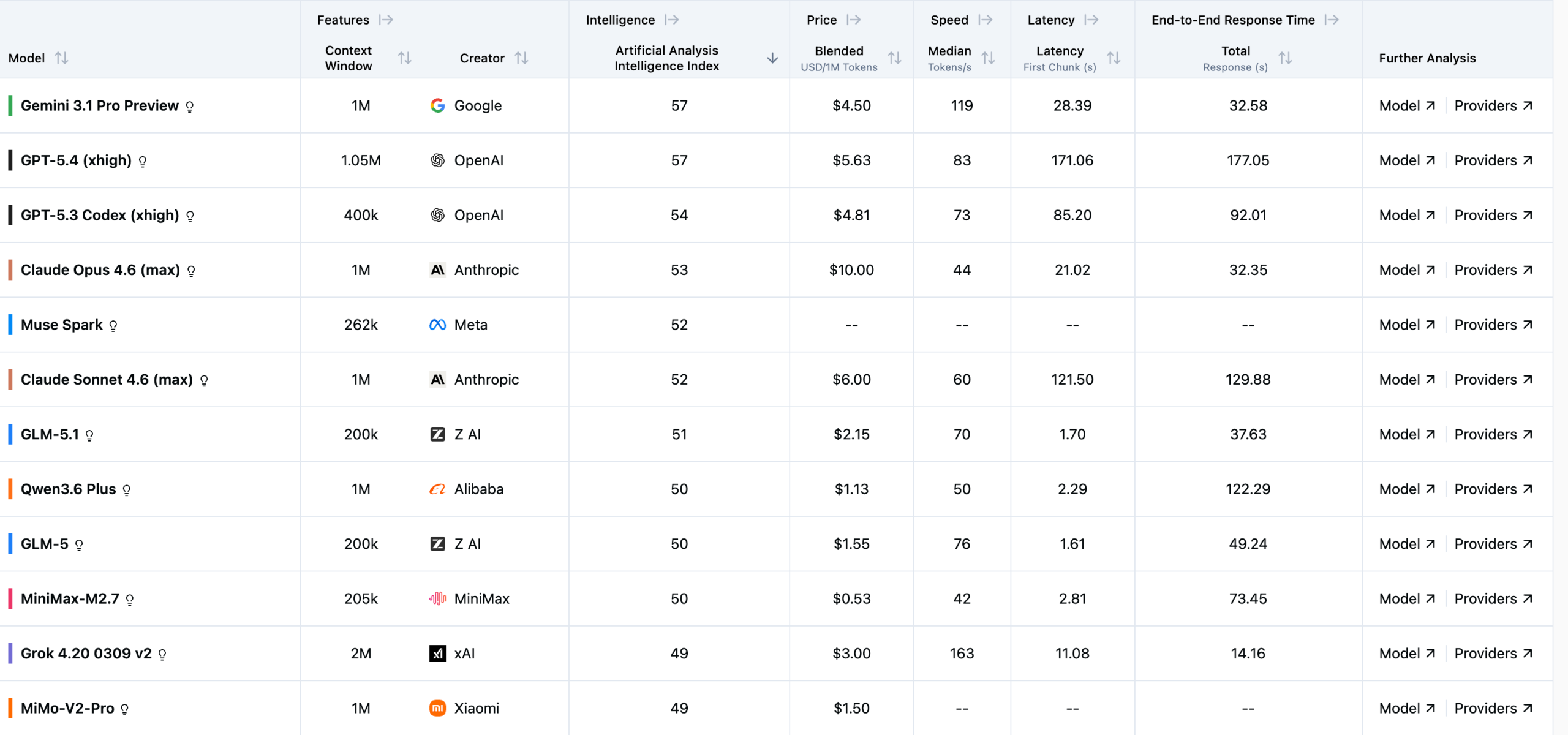
排行榜的核心是”智能指数(Intelligence Index)”,满分不限,越高越好。截至2026年4月,前五名是:
Gemini 3.1 Pro Preview(谷歌,57分)和 GPT-5.4 xhigh(OpenAI,57分)并列第一,两家打了个平手。第三是 GPT-5.3 Codex xhigh(OpenAI,54分),第四是 Claude Opus 4.6 max(Anthropic,53分),第五是 Meta 的 Muse Spark(52分)。
值得注意的是,谷歌这次是真正意义上的第一次登顶。过去几年 GPT 系列几乎是这类榜单的常客,而 Gemini 3.1 Pro 以实测分数追平 GPT-5.4,说明谷歌在推理能力上已经补上了短板。
Anthropic 的 Claude Opus 4.6 位居第四,但它的定价是每百万 token 10 美元,在头部模型里属于偏贵的。Claude Sonnet 4.6 max 以52分紧随其后,性价比稍好一些(6美元/百万token)。
速度榜:谁响应最快
如果说智能指数是”聪不聪明”,那输出速度决定的是”能不能用”。
目前最快的是 Inception 的 Mercury 2,实测达到 874 tokens/秒,远超其他模型。第二是 IBM 的 Granite 4.0 H Small(485 t/s),第三是 Granite 3.3 8B(375 t/s)。
这个速度意味着什么?普通阅读速度大约是每秒4~5个汉字,一个874 t/s 的模型,用来做实时对话完全感觉不到等待。相比之下,Claude Opus 4.6 的速度是44 t/s,差了将近20倍,但它要解决的问题类型本来就不一样。
延迟方面(首字符时间),阿里的 Qwen3.5 2B 和 Qwen3.5 0.8B 做到了最低延迟,非常适合需要快速响应的实时场景。
最便宜的模型在哪里
价格维度,阿里的 Qwen3.5 0.8B 系列拿下了最便宜的席位,仅需 $0.02/百万token,基本等于白送。紧随其后是 Google 的 Gemma 3n E4B($0.03)和 Qwen3.5 2B($0.04)。
DeepSeek V3.2 的价格是 $0.32/百万token,在同等智能指数水平(42分)的模型里属于性价比极高的选择。相比之下,OpenAI 的 GPT-5.4 Pro xhigh 要收 $67.5/百万token,算是榜单里最贵的,适合对精度要求极高、成本不敏感的场景。
开源模型:国产已经站上主力位置
榜单共有 196 个开源(开放权重)模型,占总数超过60%。
开源模型排名第一的是 GLM-5.1,由智谱 AI(Z AI)发布,智能指数51分,收费仅 $2.15/百万token。这是中国模型第一次在此类国际榜单的开源分类中拿到第一。GLM-5(50分)紧接其后,Kimi K2.5 以47分位列第三。
除此之外,阿里的 Qwen 系列在这张榜单上几乎占据了速度、价格、小尺寸模型的多个细分第一,出现频率相当高。国内还有小米 MiMo-V2-Pro(49分)、DeepSeek V3.2(42分)、百度 ERNIE 5.0、字节跳动 Doubao Seed Code 等多个模型上榜。
一些值得关注的细节
首先是上下文窗口的分化。Meta 的 Llama 4 Scout 和 xAI 的 Grok 4.1 Fast 支持高达 1000万 token 的上下文,而大多数模型在 128k~256k 之间。对于需要处理超长文档或代码库的应用场景,这个差距会直接影响选型。
其次是推理模型(Reasoning Model)的比例越来越高,目前榜单上有159个推理模型,超过总数的一半。这类模型在输出前会进行”思维链”扩展,在数学、逻辑、代码等任务上表现明显更好,但同时延迟也更高——适不适合用,取决于业务场景对实时性的要求。
还有一个趋势值得留意:越来越多的模型开始追求”小而快”而不是”大而全”。Qwen3.5 0.8B、Ministral 3B、Phi-4 Mini 这些模型在特定任务上的表现已经相当可用,部署成本却低出一个数量级。
怎么选模型
这张榜单的意义不是告诉你”用最贵的就行”,而是帮你找到你实际需求对应的最优解。
如果你要做复杂推理、深度研究,Gemini 3.1 Pro 或 GPT-5.4 是当前上限。如果是日常对话、内容生成类的业务,Claude Sonnet 4.6 或 DeepSeek V3.2 的性价比更好。如果对速度和成本都很敏感,Qwen3.5 系列几乎是现在最省钱的选择。
需要补充的是,智能指数反映的是综合推理能力,并不等于”对你的业务有用”。具体任务还是要自己跑 benchmark,或者找专门的测评服务验证。榜单是参考,不是答案。
相关新闻
-

划重点!2026两会定调:深入推进AI+ 行动,软件定制开发企业的“黄金窗口”已开启,你加入了吗?
智能经济时代,没有软件公司能置身事外——要么用AI重构产品,要么被市场重构! 2026年全国两会胜利召开,为中国新一年的发展绘就了宏伟蓝图。2026年,作为“十五五”(2026-2030)规划的开局之年,全国两会肩负着为“十五五”发展战略奠定基础的重要使命。 在此次两会期间,AI+人工智能和大数据成为了会场内外的核心议题,相关战略部署被重点纳入《政府工作报告》和《国民经济和社会发展计划报告》中。会议期间,各界代表委员积极建言献策,围绕“AI立法”、“智能体落地”、“数据安全”、“开源生态”等议题…
-

AI年代C端和B端还有什么不同?
随着人工智能技术的快速发展,人工智能正在逐渐打破消费端(C端)和企业端(B端)之间的界限。传统上,C端和B端一直被视为两种完全不同的应用系统,在用户群体、交互技术、产品逻辑等方面存在显著差异。然而,随着大型模型技术的兴起,C端和B端之间的交互边界开始变得模糊,未来的人工智能产品将不仅仅分为C端和B端,而是形成一个跨角色和场景的智能服务系统。 C端和B端:历史上不可逾越的交界线 长期以来,C端和B端都服务于不同的市场需求和用户类型。C端产品主要面向个人用户,注重个性化、即时满意度和完美的使用体验。…
-

传统ERP和新一代ERP的区别是什么?AI智能化ERP系统开发如何碰撞出火花?
简单来说,ERP系统是一套集成的企业管理软件,它就像企业的“中枢神经系统”,将公司内部所有核心部门(如财务、采购、生产、销售、人力资源等)的数据和业务流程连接在一个统一的数据库中,实现信息实时共享和流程自动化。 01 核心概念:为什么要用 ERP? 在没有 ERP 之前,企业的各个部门通常使用独立的软件或 Excel 表格管理数据: ① 财务部有自己的账本; ② 销售部有自己的客户名单; ③ 仓库有自己的库存表。 痛点:数据不互通(形成“数据孤岛”),信息滞后,容易出错。 例如,销售卖出了货,但…
-

AI时代还需要定制开发软件吗
AI大模型正在快速改变软件生产方式,很多企业开始问同一个问题:既然AI已经能自动写代码,为什么还要投入软件定制开发和系统定制开发?表面看,AI让开发更快了;但站在企业决策层的角度,真正要解决的不是“能不能写出代码”,而是“能不能支撑业务长期增长、稳定交付、可控维护”。 如果你的系统只是一次性工具,标准化产品也许够用;但一旦涉及多部门协同、复杂流程、数据治理、权限控制、合规要求和未来扩展,AI大模型只能提高效率,不能替代架构设计、业务抽象和工程管理。换句话说,AI时代不是不需要定制开发,而是更需要…
-

AI人工智能体:人类会因为ai大面积失业吗?
当AI能完成你的工作,谁来为你买单? 近年来,人工智能技术以惊人的速度渗透到各行各业。从自动驾驶汽车到智能客服,从医疗影像诊断到金融风险评估,AI正以前所未有的方式改变我们的工作生态。这种变革引发了一个紧迫的社会议题:人类会因AI大面积失业吗?本文将深入探讨AI对就业市场的真实影响,分析哪些岗位面临风险,哪些机会正在涌现。 01 哪些工作最容易被AI取代? 不是所有工作都面临同等风险。研究表明,具有以下特征的工作最易受影响: 1、高度重复性任务:数据录入、基础客服、简单文书处理 2、模式识别类工…
-

ALL IN AI:深圳正重写城市“操作系统”
鸿蒙是我国首个全栈自研操作系统,有望成为“数字中国”的安全基石和全场景的智能引擎,前景无限。而深圳市龙岗区正是鸿蒙系统的策源地,拥有华为、中软等一批龙头企业和110多家鸿蒙生态相关企业。 2026年初,当全世界都在讨论新一轮AI浪潮的时候,深圳一个区冲了出来,提出了“All in AI”战略。 是谁这么敢?答案是深圳市光明区。它的手里握了哪些“硬牌”? 01 龙岗“样板间”:从“工业第一区”到“操作系统”重写 作为全国工业百强区的“七连冠”,龙岗区拥有5901.27亿元GDP的雄厚制造业基因,这…
-

AI原生嵌入ERP:智能体+大模型正在改变企业管理系统的底层玩法
上个月跟一个做五金配件的老板聊天,他说了句特别实在的话:”我花了两百万上ERP,现在最大的感受就是——以前手工记错账,现在系统里记错账。” 他不是在否定ERP的价值。流程确实规范了,数据确实集中了。但业务员每天花大量时间在系统里录单、翻菜单、跨模块找数据,干的全是”伺候系统”的活。ERP本来应该是工具,结果活成了负担。 这个问题不是个例。很多企业的ERP系统用了五年八年,流程跑得通但效率上不去。不是系统不行,是它太”死”了—…
-

OpenClaw 能干什么?一个重度用户的 10 个真实用例拆解
OpenClaw非常火爆非常强大,但它也很危险!本文提供最基础的场景介绍,看官按自己的承受能力选择使用 近年来,OpenClaw 龙虾在国内外的技术圈爆火,吸引了众多关注。但与其大量的理论讨论、架构发展方向相比,真正的应用场景却少有人深入剖析。 那么,OpenClaw到底能为我们的日常工作提供哪些切实可行的功能呢?作为一个具备开发能力的用户,我们通过一系列实际案例,展示了OpenClaw的多种应用。通过这些用例,我们能更清晰地看到它如何影响和提升工作效率。 Clawd诞生于2025年11月——这…
-

大厂的牛马,也在被迫用AI
“被迫用AI”,这或许是2026年大厂员工最真实的写照。曾经被视为提效神器的AI,如今正以一种复杂甚至矛盾的姿态,深度嵌入我们的日常工作。它既是晋升的阶梯,也是悬在头顶的达摩克利斯之剑。 01 Token与Skill:悬在头顶的新KPI 在不少大厂,AI的使用早已从“鼓励”变成了“强制”。你的绩效,可能正与两个新指标紧密挂钩:Token消耗量和Skill产出量。 1)Token消耗量:这成了衡量你是否积极拥抱AI的“硬通货”。部门内部甚至搭起了排行榜,谁消耗的Token多,谁的绩效就可能更高。有…
-

小企业为何也需要ERP系统:为AI落地打下基础
很多人可能会认为 ERP系统 只适合大企业,尤其是那些需要管理复杂生产流程的大型公司。其实,随着技术的发展,现在的 ERP定制开发 也越来越适合中小型企业。 对于这些企业来说,ERP不仅仅是一个管理工具,它更是实现 AI技术应用 的基础。你可能会觉得小企业用不上这么复杂的系统,但实际上,ERP系统能够帮助企业整合数据和优化流程,这些正是成功落地AI的前提。如果没有一个稳定的数据来源和高效的业务流程,AI的应用就无法发挥真正的作用。 不使用ERP系统的小企业面临的挑战 数据孤岛与信息滞后 没有ER…
