
从经验驱动到算法驱动:企业班车管理系统定制方案深度解析
某制造企业在接入智能班车系统后,车辆从12辆减至9辆,满座率从68%提升至89%,行政每月调度时间从20小时降至2小时。这不是个例。通过对华为、OPPO等超1000家企业通勤数据的跟踪,我们发现73%的企业班车存在线路迂回、空驶率高的问题,每年造成20%以上的交通预算浪费。本文将站在技术实现角度,拆解企业班车管理系统定制的核心逻辑。
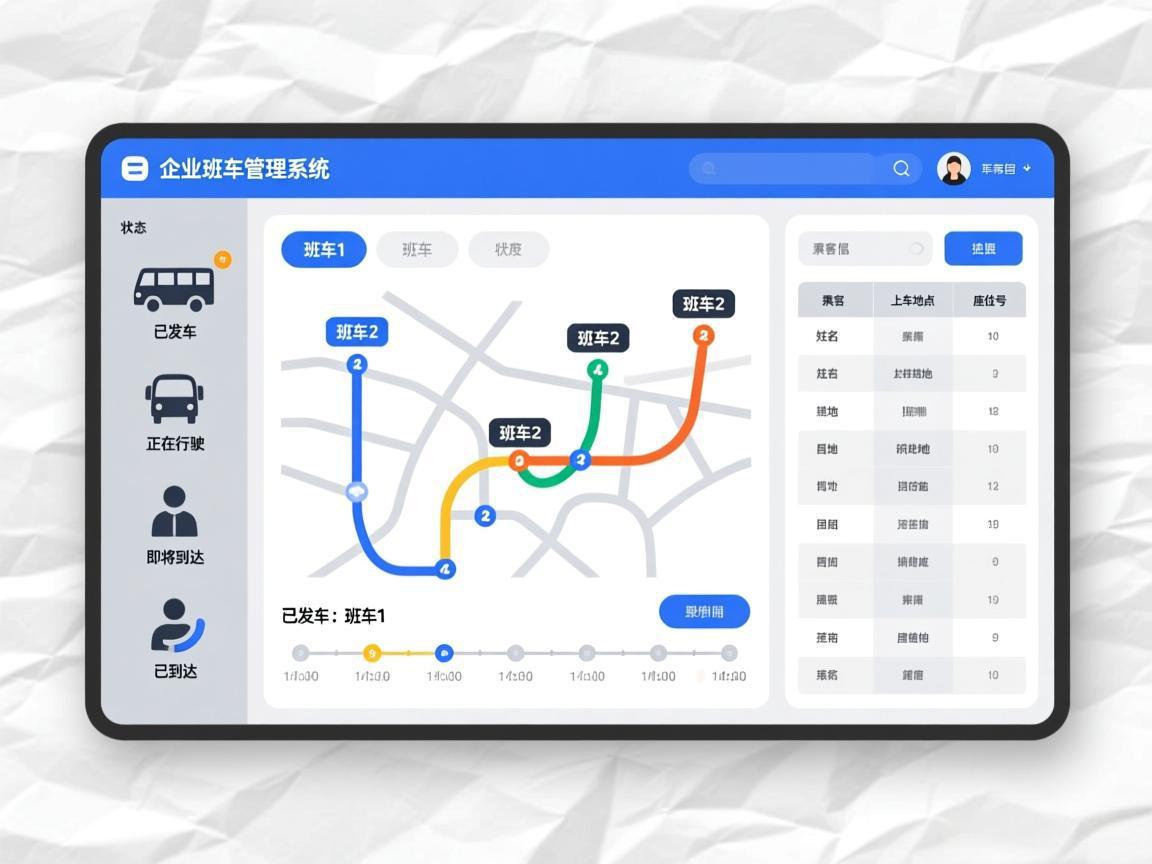
一、传统班车管理的“隐性成本黑洞”
企业在班车管理上面临三重割裂:员工需求与线路规划割裂,导致部分站点空驶率高、部分员工无车可坐;业务数据与财务核算割裂,华为案例显示,传统模式下“1张票贴票成本高达18美金”,年度交通费用超3000万的企业,仅财务审核就耗费大量人力;车辆运营与动态路况割裂,遇到拥堵或管制,司机无法及时通知员工,投诉率居高不下。
二、定制系统技术架构的核心模块
1. 多源数据集成层:解决“数据孤岛”问题
定制系统的底层逻辑是数据贯通。员工侧需采集通勤地址(通过GIS地理围栏技术脱敏处理)、乘车时段偏好、历史取消率;车辆侧需接入实时定位、速度、能耗及驾驶员工时数据。数据清洗规则需自动过滤无效地址、合并500米内相似需求点,并建立员工信用分模型,减少恶意占座干扰。
2. 动态路径优化引擎:从“固定线路”到“动态生长”
核心算法采用贪心+遗传混合模型:先通过贪婪算法快速生成满足基本覆盖的初级线路,再用遗传算法模拟数百万次迭代,筛选出成本最优的拓扑结构。在实际部署中,系统需支持可视化沙盘推演——管理员可拖动设置临时禁停点,系统实时重算路径并对比成本差异。
更关键的是强化学习机制:系统根据历史调度效果自动调整权重参数。某3万人厂区案例显示,采用MongoDB存储海量轨迹数据、Kafka处理高并发刷卡数据后,应急响应时间从传统模式的2小时以上压缩至8分钟。
3. 资源利用率监控与预警
系统需建立核心指标体系:空驶率(非载客里程比例)应从传统的35%降至12%以内;需求覆盖率需达到员工地址5公里内98%以上。当某线路连续3天空驶率超15%,系统自动推送合并建议;当某区域需求增长超阈值,提前提示增补车辆。
三、跨平台集成与财务自动化
定制系统必须与企业现有IT生态无缝对接。支持钉钉/企微/飞书等入口,员工在办公软件内即可完成查车、预约、刷码乘车。自动分账体系是财务侧的核心价值——系统每月自动生成部门乘车费用分摊报表,华为采用后“每年节省10%以上出行成本”。
技术架构上推荐B/S模式,前端采用React/Vue,后端Java Spring Boot或Node.js,数据库选MySQL/PostgreSQL配合Redis缓存热点数据。关键业务接口需设计熔断与降级策略,保障第三方地图服务异常时系统仍正常运行。
四、案例验证:算法驱动的降本增效
某制造企业接入定制系统后,通过聚类算法对员工地址进行密度分析,重新规划站点,班车数量从12辆优化至9辆,单次覆盖人数增加40%。OPPO通过上线包车订单管理系统,部门用车申请、审批、派车全流程线上化,解决了过去邮件电话报备“无记录、不可追溯”的痛点。
五、技术趋势展望
企业班车系统正从“信息化”向“智能化”演进。碳足迹规划模块开始进入头部企业需求清单——系统自动优先调度新能源车辆,根据充电桩分布优化线路,并生成《班车碳减排报告》辅助ESG评级。无人接驳巴士在封闭场景的试点也已启动,预计未来三年将重构园区通勤形态。
对于技术负责人而言,选型班车管理系统不应只看功能列表,而需评估:数据接入的标准化能力、算法模型的迭代机制、以及供应商在大型企业的落地验证。这套系统的本质,是用算法取代经验,让每公里的运力都产生明确价值。
